드디어 스프링 수업 시작!
웹 동작 방식
▶️ IP 주소?
- 거대한 네트워크망에서 여러분의 컴퓨터를 식별하기 위한 위치 주소
- 네트워크상에서의 데이터 송/수신은 IP 주소 기준
▶️ 브라우저?
- 크롬, 사파리, 엣지와 같이 웹페이지, 이미지, 비디오 등의 콘텐츠를 송/수신하고 표현해주는 소프트웨어
▶️ DNS(Domain Name Server)?
- 우리의 IP 주소와 브라우저의 Domain 주소를 연결시켜주는 서버
▶️ HTTP?
- 프로토콜 : DNS에서 송/수신 시 약속된 방식으로만 클라이언트와 브라우저가 보낼 수 있게 해 놓은 것
Request URL : www.naver.com // 주소
Address : 192.0.0.1 // 자신의 IP주소
…
Request Body : “네이버 첫 페이지 데이터 좀 주세요!” // 보내고자 하는 정보를 ':'로 구분하여 정보 전달
▶️ API(Application Programming Interface)?

- HTTP 프로토콜로 인해 받은 클라이언트의 요청을 다른 소프트웨어 시스템과 통신하기 위해 따라야 하는 규칙
- 웹 API는 클라이언트와 웹 리소스 사이의 게이트웨이라고 생각할 수 있다.
▶️ 인터페이스(interface)?
- 서로 다른 두 개의 시스템, 장치 사이에서 정보나 신호를 주고받는 경우의 접점이나 공유 경계면
- 소프트웨어, 컴퓨터 하드웨어, 주변기기, 사람 간에 이루어질 수 있으며, 서로 복합적으로 이루어질 수도 있다.
👉예시
from flask import Flask
def create_app():
app = Flask(__name__)
@app.route('/PrintHelloWorld')
def hello_world():
return 'Hello, World!'
@app.route('/HelloWorldTemplate')
def hello_world():
return render_template('HelloWorldTemaplate")
return app도메인 이름 뒤에 오는 양식을 맞춰주기만 하면 플라스크가 알아서 해당 함수를 호출해줬던 것을 떠올려보자.
만약 우리의 도메인이 (www.serverDeveloper.com)이고, 도메인 뒤에 @app.route()안에 들어간 정보들을 써주면, 해당 어노테이션이 붙어있는 함수가 호출된다.
www.serverDeveloper.com/HelloWorldTemplate
⇒ HelloWorldTemplate이라는 html/css/javascript로 구성된 template이 클라이언트로 전송되어 브라우저가 그려주게 된다. 아마도 해당 template에는 그 “웹페이지”안에서 다른 요청을 보낼 수 있는 ajax와 같은 코드들도 포함되어 있어 연속적으로 웹페이지를 이용할 수 있게 한다.
즉 @app.route()와 같은 표시가 붙은 함수들이 사용자들의 요청을 가장 먼저 맞이해주는 역할을 해줬고, 이러한 역할과 명세를 잘 정리해두면 api 명세가 되고, 우리 서버 프로그램이라는 식당의 점원 역할을 한 것이다.
▶️ RESTful API?
- API 작동 방식에 대한 조건을 부과하는 소프트웨어 아키텍처
인데 일단 REST가 뭔지 알아야 한다.
❗ REST?
- 인터넷과 같은 복잡한 네트워크에서 통신을 관리하기 위한 지침
REST 기반 아키텍처를 사용하여 대규모의 고성능 통신을 안정적으로 지원할 수 있다. 쉽게 구현하고 수정할 수 있어 모든 API 시스템을 파악하고 여러 플랫폼에서 사용할 수 있다.
- REST 아키텍처 스타일을 따르는 API를 REST API
이 REST 아키텍처를 구현하는 웹 서비스를 RESTful 웹 서비스라고 한다. RESTful API라는 용어는 일반적으로 RESTful 웹 API를 나타낸다. 하지만 REST API와 RESTful API라는 용어는 같은 의미로 사용할 수 있다.

예를 들어 api의 리소스 식별자를 ex - (”/”) 중복 없이 고유하게 잘 만들고, 해당 api에 적절하게 http메서드를 사용했다면, RESTful 하게 설계했다고 볼 수 있다.
▶️ 서버가 요청을 처리하기 위한 자료들?
서버로 특정한 요청을 처리하는데, 필요한 것이 하나 더 있다.

👉 예시
@app.route('/sign_in', methods=['POST'])
def sign_in():
username_receive = request.form['username_give']
password_receive = request.form['password_give']
pw_hash = hashlib.sha256(password_receive.encode('utf-8')).hexdigest()
# 여기!!!!
result = db.users.find_one({'username': username_receive, 'password': pw_hash})
if result is not None:
payload = {
'id': username_receive,
'exp': datetime.utcnow() + timedelta(seconds=60 * 60 * 24) # 로그인 24시간 유지
}
token = jwt.encode(payload, SECRET_KEY, algorithm='HS256')
return jsonify({'result': 'success', 'token': token})
else:
return jsonify({'result': 'fail', 'msg': '아이디/비밀번호가 일치하지 않습니다.'})클라이언트의 요청이 네트워크를 타고 들어와서, “새로운 정보”인 유저의 ID/Password를 들고 들어왔다.
@app.route('/sign_in', methods=['POST'])이제는 위와 같은 어노테이션을 통해 sign_in 메서드가 요청을 처리하기 위해 점원의 역할을 한다는 것도 알게 됐다.
하지만 우리에게는 한 가지 정보가 더 필요합니다. 바로 “기존의 정보”이다.
기존의 정보가 있어야 유저가 로그인을 시도하려는 아이디 비밀번호와 같이 대조해 볼 수 있다.
그리고 그러한 정보는 이미 생성되어 가지고 있거나, 서버의 동작을 통해서(예를 들어 회원 가입과 같은) 저장되어 활용이 가능해야 한다.
이러한 역할을 해 주는 것이 내가 계속 썼었던 몽고 DB나 SQL과 같은 데이터베이스이다. 위의 주석 처리된 '여기' 부분이 몽고 DB 부분인데, 몽고 DB는 빅데이터 등 특정 도메인에서 매우 유용하지만, 우리가 앞으로 처리할 다양한 상황에서 아쉬운 점이 있다. 그래서 관계형 데이터베이스에 대해서도 알아볼 예정이다.
🤔 데이터베이스는 왜 있으며, 왜 다양한 종류가 있을까?
👉 처음 접하는 분들이 가장 쉽게 오해하기로는, “정해진 공간에 최대한 많은 데이터를 저장하기 위해서”라고 생각할 수 있다. 하지만 사실 데이터베이스는 데이터를 “효율적으로 성능 좋게” 다루기 위해 존재한다.
즉, 더 많이 저장하기 위해서가 아니라 저장 조회 수정 삭제 등을 더 빠르고 효율적으로 처리하기 위해서 “성능상의 이점”을 얻기 위해서 사용한다고 생각하면 좋다.
이러한 맥락에서 데이터를 사용, 활용하는 주체에 따라서 더 효율적인 방법이 각각 다르다 보니 다양한 형식의 데이터베이스가 존재하게 됩니다.
▶️ 서버 개발
서버 개발에서 가장 많이 하는 일은 “새로운 정보”와 “기존의 정보”를 가지고 “정해진 로직”을 수행하는 일이다.
이를 위해서는 다음 3가지를 위에서 이야기한 것이다.
0. 기존에 알고 있던 웹 프로그램이 어떻게 동작하는지
1. 어떻게 새로운 정보인 클라이언트의 요청이 서버로 도달하는지
2. 어떻게 기존의 정보를 저장하는지
스프링 부트 및 서버
▶️ 소프트웨어 디자인 패턴(software design pattern)
- 소프트웨어 공학의 소프트웨어 디자인에서 특정 문맥에서 공통적으로 발생하는 문제에 대해 재사용 가능한 해결책
- 소스나 기계 코드로 바로 전환될 수 있는 완성된 디자인은 아니며, 다른 상황에 맞게 사용될 수 있는 문제들을 해결하는 데에 쓰이는 서술이나 템플릿
- 디자인 패턴은 프로그래머가 애플리케이션이나 시스템을 디자인할 때 공통된 문제들을 해결하는 데에 쓰이는 형식화된 가장 좋은 관행
Software Architecture Patterns
Chapter 1. Layered Architecture The most common architecture pattern is the layered architecture pattern, otherwise known as the n-tier architecture pattern. This pattern is the de facto standard for most … - Selection from Software Architecture Pattern
www.oreilly.com
▶️ 복잡하면 나누자!
서버는 “새로운 데이터를 처리하는 부분”, “서비스 로직을 처리하는 부분”, “기존의 데이터를 이용하는 부분”으로 되어 있다.

👉 Presentation 계층
사용자와 상호 작용 처리 계층
CLI, HTTP 요청, HTML 처리 등을 담당한다.
HTTP 요청 처리 및 HTML 렌더링에 대해 알고 있는 웹 계층
흔히 말하는 MVC (Model / View / Controller) 도 이 계층에 속한다.
우리가 URL을 매핑해서 특정 메서드가 해당 URL로 요청이 올 때마다 호출되게 프로그래밍했던 그 계층을 말하는 것이며, 스프링에서는 @Controller 어노테이션을 사용하여 표현한다.
👉 Domain(Business or Service) 계층
서비스/시스템의 핵심 로직
유효성 검사 및 계산을 포함하는 Business 논리 계층
애플리케이션이 수행해야 하는 도메인과 관련된 작업들을 담당한다.
입력/저장된 데이터를 기반으로 계산
Presentation 계층에서 받은 데이터의 유효성 (Validation) 검사
어떤 Data Access를 선택할지 결정
서버 프로그램이 복잡해지면, 비즈니스 로직을 수행하기 위한 별도의 계층(Layer)이 필요하다. 사실 더 이상적으로는 유능한 서버 프레임워크를 써서 Presentaion, Data Access계층에는 별로 할 일이 없고, 도메인 계층이 비대해지는 게 가장 좋다. 스프링에서는 @Service 어노테이션을 사용해서 표현한다.
👉 Data Access(Persistence) 계층
DAO 계층
Database / Message Queue / 외부 API와의 통신 등 처리
데이터베이스 또는 원격 서비스에서 영구 데이터를 관리하는 방법을 분류하는 데이터 접근 계층
데이터베이스, 혹은 데이터를 저장하는 데이터 소스는 서버 외부에 별개로 존재하는 경우가 매우 많고, 그러한 데이터 소스와의 소통을 해주는 계층이라고 생각하면 된다. 스프링에서는 @Repository 어노테이션을 사용해서 표현한다.

레이어드 아키텍처 패턴과 관련해선 아래 링크 참조!
계층형 아키텍처
학교 다닐때 잠깐 JAVA 관련 수업을 들은적이 있다. 그때 수업 내용은 넷빈즈(Netbeans) IDE를 통해 JAVA로 윈도우 애플리케이션을 만드는 것이였다. 간단한 시간표 관리 프로그램을 만드는 과제는 얼
jojoldu.tistory.com
🔑 Controller, Service, Respository 실제 코드들
👉 Controller
@Controller // #1
public class ContentController {
private final ContentService contentService; // #2
@GetMapping("/content/{contentId}") // #3
public Content getContent(@PathVariable Long contentId) { // #4
Content content = contentService.getContent(requestDto); //#2-1
return "/contentPage";
}
@PostMapping("/content") //#5
@ResponseBody// #6
public Content createContent(@RequestBody ContentRequestDto requestDto) {
Content content = contentService.createContent(requestDto);
return content;
}
}#1 : 이 자바 객체가 컨트롤러 역할을 하는 객체라는 것을 알려주는 어노테이션
#2 : 각각의 레이어는 “일반적으로” 자기와 인접한 레이어와 직접 소통. 이 경우 ContentService객체를 가지고 있어, 컨트롤러 단에서 서비스 단으로 새로 받아온 데이터를 전달하거나 서비스 로직을 호출할 수 있다. (예를 들어 #2-1)
#3 : 플라스크의 @app.route(”/”)와 비슷하다. 특정 요청에 호출될 메서드를 지정해주는 어노테이션
#4 : 해당 메서드에 넘기는 인자 값을 손쉽게 넘기도록 이와 같은 어노테이션을 사용할 수 있다. 이러한 어노테이션이 있으면 자동으로 일치하는 변수 값을 메서드 호출되는 시점에 같이 넘겨준다.
#5 : #3과 #5가 다른 이유는 HttpMethod에 따라서 다른 Controller 메서드를 연결해줄 수 있기 때문이다. 같은 주소로 온 GET 요청과 POST을 나눠서 각각 처리하기에 용이하다.
#6 : 위의 메서드와 아래의 메서드는 이전에 배웠던, 뷰까지 같이 반환하느냐, 혹은 JSON 형식으로 데이터만 반환하느냐의 차이가 있다.
👉 Service
@Service // #1
public class ContentService {
private final ContentRepository contentRepository; //#2
public ReturnDto getContent(Long id) {
ReturnDto returnDto = contentRepository.findById(id);
return returnDto; //#3
}
public Content createContent(ContentRequestDto contentRequestDto) {
Content content = new Content(contentRequestDto);
contentRepository.save(content);
return content;
}
}#1 : 마찬가지로 이 자바 객체가 서비스 역할을 하는 객체라는 것을 알려주는 어노테이션
#2 : 인접한 계층인 Repository 객체를 가지고 있어야 한다.
#3 : 이 부분 역시 인접한 계층으로 데이터를 전달한다.
👉 Respository
@Repository // #1
public interface ContentRepository extends JpaRepository<Content, Long> {
// #2
}#1 : 마찬가지로 이 자바 객체가 서비스 역할을 하는 객체라는 것을 알려주는 어노테이션.
#2 : 사실 리포지토리는 상당히 다양한 기술과 얽혀 있고, 다양한 케이스가 있어 예시 코드를 보여드리기는 조금 어렵다. 앞으로 용하게 될 SpringDataJpa의 JpaRepository는 이런 식으로 쓸 수 있다. 이 부분은 실습을 통해서 감을 익히자!
▶️ IOC? DI?
private final ContentService contentService; // #2
private final ContentRepository contentRepository; //#2자바를 공부하고, 스프링만 처음이라면 위와 같은 코드의 위화감을 느낄 수 있다(는 나).
분명 해당 객체의 메서드도 호출하고 있는데, 해당 객체는 어디서 어떻게 들어와 있을까?
이외에도 앞으로 지엽적인 컨트롤러나 리포지토리 서비스 쪽 코드를 보다 보면 자바 문법과 묘하게 다른 부분들이 보이게 된다. 때로 어떠한 지식은 뒤의 내용을 알아야 이해가 더 쉬운 경우가 있어 지금은 그냥 넘어가겠지만 위와 같이 기존까지 알고 계시던 자바 문법과 다른 부분은 꼭 메모를 하시고 의아해하는 습관을 가지면, 이후 IOC, DI 등 설계 철학 등을 배우고 이해하는데 큰 자산이 된다.
▶️스프링/스프링 부트를 사용하는 이유?
일반적으로 가장 많이 꼽는 이유로는, 단순 반복 작업 부분이 많았던 Controller와 Repository 쪽을 개발 관점에서 매우 쉽고 편하게 처리해줘 가장 중요한 핵심 비즈니스 로직인 Service 레이어에 더 집중할 수 있도록 하게 해 준다는 이유를 꼽기도 한다.
라고 하셨다. 이 부분은 내가 직접 해 보면서 느낀 점을 나중에 추가해봐야겠다.
데이터베이스와 SQL
▶️ Database
- 한 마디로 정의하면 ‘데이터의 집합’ 이다.
💡 용어
- DBMS
- DBMS 는 ‘Database Management System’ 의 약자로 Database를 관리하고 운영하는 소프트웨어를 의미한다.
- RDBMS
- RDBMS는 ‘Relational DBMS’의 약자로 관계형 데이터베이스라고 불린다.
- RDBMS는 테이블(table)이라는 최소 단위로 구성되며, 이 테이블은 열(column)과 행(row)으로 이루어져 있다.
| 아이디 | 이름 | 전화번호 | 그룹 | column 명 |
| ka123 | 카즈하 | 010-7777-7777 | 르세라핌 | 1 row |
| kim123 | 김채원 | 010-6666-6666 | 르세라핌 | 2 row |
| sa123 | 사쿠라 | 010-8888-8888 | 르세라핌 | 3 row |
| heo123 | 허윤진 | 010-0000-0000 | 르세라핌 | 4 row |
| hong123 | 홍은채 | 010-1111-1111 | 르세라핌 | 5 row |
- MySQL, PostgreSQL, Oracle Database 가 있고 실제 배포시 MySQL을 많이 이용한다.
튜터님은 H2와 MySQL을 이용한다고 하셨다.
-H2 : 인메모리 DB란 서버가 작동하는 동안에만 내용을 저장하고, 서버가 작동을 멈추면 데이터가 모두 삭제되는 데이터베이스
▶️ SQL(Structured Query Language)
- RDBMS에서 사용되는 언어(수 많은 정보를 Database에서 조작하고 관리하기 위해서는 SQL 언어를 사용해야 한다.)
- DBMS를 만드는 회사가 여러 곳이기 때문에 DBMS 마다 표준 SQL을 준수하되, 각 제품의 특성을 반영하기 위한 약간의 차이가 존재한다.
👉 DDL(Data Definition Language)
- 테이블이나 관계의 구조를 생성하는데 사용
- CREATE : 새로운 데이터베이스 및 테이블을 생성해 준다.
🗝️제약조건
1. AUTO_INCREMENT : 컬럼의 값이 중복되지 않게 1씩 자동으로 증가하게 해줘 고유번호를 생성해준다.
2. NOT NULL : 해당 필드는 NULL 값을 저장할 수 없게 된다.
3. UNIQUE : 해당 필드는 서로 다른 값을 가져야만 한다.
4. PRIMARY KEY : 해당 필드가 NOT NULL과 UNIQUE 제약 조건의 특징을 모두 가지게 된다.
5. FOREIGN KEY : 하나의 테이블을 다른 테이블에 의존하게 만들며 데이터의 무결성을 보장해준다.
6. CASCADE : FOREIGN KEY 로 연관된 데이터를 삭제,변경할 수 있다.
CREATE DATABASE 데이터베이스이름;
CREATE TABLE 테이블이름
(
필드이름1 필드타입1,
필드이름2 필드타입2,
...
);- ALTER : 데이터베이스와 테이블의 내용을 수정할 수 있다.
ALTER TABLE 테이블이름 ADD 필드이름 필드타입;
ALTER TABLE 테이블이름 DROP 필드이름;
ALTER TABLE 테이블이름 MODIFY COLUMN 필드이름 필드타입;
- DROP : 데이터베이스와 테이블을 삭제할 수 있다. 데이터 및 테이블 전체를 삭제한다.
DROP DATABASE 데이터베이스이름;
DROP TABLE 테이블이름;- TRUNCATE : 데이터베이스와 테이블을 삭제할 수 있다. 최초 테이블이 만들어졌던 상태 즉, 컬럼값만 남긴다.
TRUNCATE DATABASE 데이터베이스이름;
TRUNCATE TABLE 테이블이름;
👉 DCL(Data Control Language)
- 데이터의 사용 권한을 관리하는데 사용
- GRANT : 사용자 또는 ROLE에 대해 권한을 부여할 수 있다.
GRANT [객체권한명] (컬럼)
ON [객체명]
TO { 유저명 | 롤명 | PUBLC} [WITH GRANT OPTION];
//ex
GRANT SELECT ,INSERT
ON mp
TO scott WITH GRANT OPTION;- REVOKE : 사용자 또는 ROLE에 부여한 권한을 회수할 수 있다.
REVOKE { 권한명 [, 권한명...] ALL}
ON 객체명
FROM {유저명 [, 유저명...] | 롤명(ROLE) | PUBLIC}
[CASCADE CONSTRAINTS];
//ex
REVOKE SELECT , INSERT
ON emp
FROM scott
[CASCADE CONSTRAINTS];
👉 DML(Data Manipulation Language)
- 테이블에 데이터를 검색, 삽입, 수정, 삭제하는데 사용
- INSERT : 테이블에 새로운 row를 추가할 수 있다.
INSERT INTO 테이블이름(필드이름1, 필드이름2, 필드이름3, ...) VALUES(데이터값1, 데이터값2, 데이터값3, ...);
INSERT INTO 테이블이름 VALUES(데이터값1, 데이터값2, 데이터값3, ...);- SELECT : 테이블의 row를 선택할 수 있다.
SELECT 필드이름 FROM 테이블이름 [WHERE 조건];- UPDATE : 테이블의 row의 내용을 수정할 수 있다.
UPDATE 테이블이름 SET 필드이름1=데이터값1, 필드이름2=데이터값2, ... WHERE 필드이름=데이터값;- DELETE : 테이블의 row를 삭제할 수 있다.
DELETE FROM 테이블이름 WHERE 필드이름=데이터값;
👉 실습
[CREATE_MAJOR]
CREATE TABLE IF NOT EXISTS MAJOR
(
major_code varchar(100) primary key comment '주특기코드',
major_name varchar(100) not null comment '주특기명',
tutor_name varchar(100) not null comment '튜터'
)[CREATE_STUDENT]
CREATE TABLE IF NOT EXISTS STUDENT
(
student_code varchar(100) primary key comment '수강생코드',
name varchar(100) not null comment '이름',
birth varchar(8) null comment '생년월일',
gender varchar(1) not null comment '성별',
phone varchar(11) null comment '전화번호',
major_code varchar(100) not null comment '주특기코드',
foreign key(major_code) references major(major_code)
)[CREATE_EXAM]
CREATE TABLE IF NOT EXISTS EXAM
(
student_code varchar(100) not null comment '수강생코드',
exam_seq int not null comment '시험주차',
score decimal(10,2) not null comment '시험점수',
result varchar(1) not null comment '합불'
)
[ALTER]
위의 EXAM에 PK, FK를 연결해줌
ALTER TABLE EXAM
ADD PRIMARY KEY (student_code, exam_seq);
ALTER TABLE EXAM
ADD CONSTRAINT exam_fk_student_code FOREIGN KEY (student_code) REFERENCES STUDENT (student_code);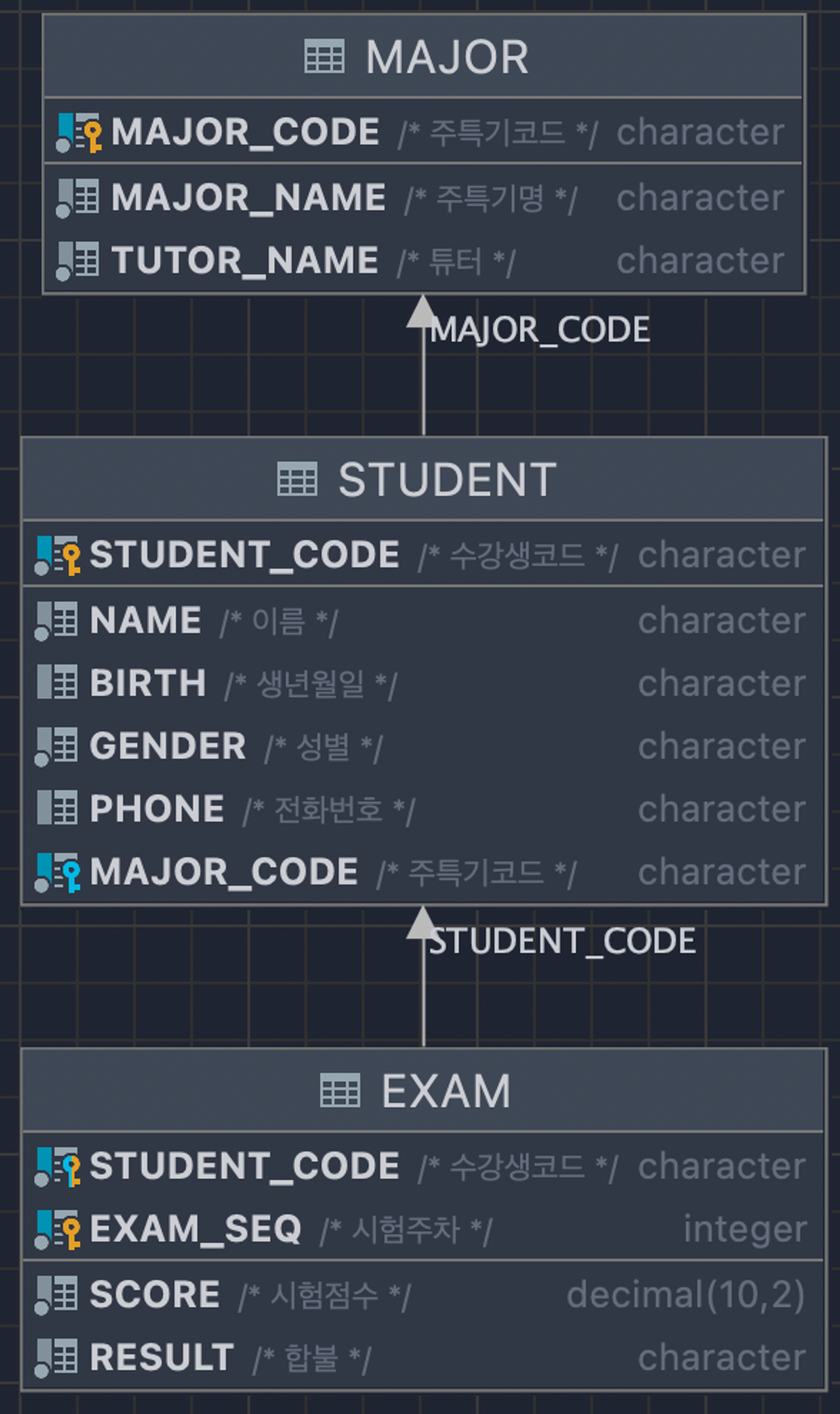
[INSERT_MAJOR]
INSERT INTO MAJOR VALUES('m1', '스프링', '남병관');
INSERT INTO MAJOR VALUES('m2', '노드', '강승현');
INSERT INTO MAJOR VALUES('m3', '플라스크', '이범규');
INSERT INTO MAJOR VALUES('m4', '루비온레일즈', '차은서');
INSERT INTO MAJOR VALUES('m5', '라라벨', '구름');
INSERT INTO MAJOR VALUES('m6', '리엑트', '임민영');
INSERT INTO MAJOR VALUES('m7', '뷰', '김서영');
INSERT INTO MAJOR VALUES('m8', '엥귤러', '한현아');[INSERT_STUDENT]
INSERT INTO STUDENT VALUES('s1', '최원빈', '20220331', 'M', '01000000001', 'm1');
INSERT INTO STUDENT VALUES('s2', '강준규', '20220501', 'M', '01000000002', 'm1');
INSERT INTO STUDENT VALUES('s3', '김영철', '20220711', 'M', '01000000003', 'm1');
INSERT INTO STUDENT VALUES('s4', '예상기', '20220408', 'M', '01000000004', 'm6');
INSERT INTO STUDENT VALUES('s5', '안지현', '20220921', 'F', '01000000005', 'm6');
INSERT INTO STUDENT VALUES('s6', '이대호', '20221111', 'M', '01000000006', 'm7');
INSERT INTO STUDENT VALUES('s7', '정주혜', '20221117', 'F', '01000000007', 'm8');
INSERT INTO STUDENT VALUES('s8', '고미송', '20220623', 'F', '01000000008', 'm6');
INSERT INTO STUDENT VALUES('s9', '이용우', '20220511', 'M', '01000000009', 'm2');
INSERT INTO STUDENT VALUES('s10', '심선아', '20220504', 'F', '01000000010', 'm8');
INSERT INTO STUDENT VALUES('s11', '변정섭', '20220222', 'M', '01000000020', 'm2');
INSERT INTO STUDENT(student_code, name, gender, major_code) VALUES('s12', '권오빈', 'M', 'm3');
INSERT INTO STUDENT VALUES('s13', '김가은', '20220121', 'F', '01000000030', 'm1');
INSERT INTO STUDENT(student_code, name, gender, major_code) VALUES('s14', '김동현', 'M', 'm4');
INSERT INTO STUDENT VALUES('s15', '박은진', '20221101', 'F', '01000000040', 'm1');
INSERT INTO STUDENT(student_code, name, birth, gender, phone, major_code) VALUES('s16', '정영호', '20221105', 'M', '01000000050', 'm5');
INSERT INTO STUDENT(student_code, name, gender, major_code) VALUES('s17', '박가현', 'F', 'm7');
INSERT INTO STUDENT(student_code, name, birth, gender, phone, major_code) VALUES('s18', '박용태', '20220508', 'M', '01000000060', 'm6');
INSERT INTO STUDENT VALUES('s19', '김예지', '20220505', 'F', '01000000070', 'm2');
INSERT INTO STUDENT VALUES('s20', '윤지용', '20220909', 'M', '01000000080', 'm3');
INSERT INTO STUDENT VALUES('s21', '손윤주', '20220303', 'F', '01000000090', 'm6');[INSERT_EXAM]
INSERT INTO EXAM VALUES('s1', 1, 8.5, 'P');
INSERT INTO EXAM VALUES('s1', 2, 9.5, 'P');
INSERT INTO EXAM VALUES('s1', 3, 3.5, 'F');
INSERT INTO EXAM VALUES('s2', 1, 8.2, 'P');
INSERT INTO EXAM VALUES('s2', 2, 9.5, 'P');
INSERT INTO EXAM VALUES('s2', 3, 7.5, 'P');
INSERT INTO EXAM VALUES('s3', 1, 9.3, 'P');
INSERT INTO EXAM VALUES('s3', 2, 5.3, 'F');
INSERT INTO EXAM VALUES('s3', 3, 9.9, 'P');
INSERT INTO EXAM VALUES('s4', 1, 8.4, 'P');
INSERT INTO EXAM VALUES('s5', 1, 9.5, 'P');
INSERT INTO EXAM VALUES('s5', 2, 3.5, 'F');
INSERT INTO EXAM VALUES('s6', 1, 8.3, 'P');
INSERT INTO EXAM VALUES('s7', 1, 9.2, 'P');
INSERT INTO EXAM VALUES('s7', 2, 9.9, 'P');
INSERT INTO EXAM VALUES('s7', 3, 3.6, 'F');
INSERT INTO EXAM VALUES('s8', 1, 8.4, 'P');
INSERT INTO EXAM VALUES('s9', 1, 9.7, 'P');
INSERT INTO EXAM VALUES('s10', 1, 8.4, 'P');
INSERT INTO EXAM VALUES('s10', 2, 9.8, 'P');
INSERT INTO EXAM VALUES('s10', 3, 8.4, 'P');
INSERT INTO EXAM VALUES('s11', 1, 8.6, 'P');
INSERT INTO EXAM VALUES('s12', 1, 9.2, 'P');
INSERT INTO EXAM VALUES('s13', 1, 8.1, 'P');
INSERT INTO EXAM VALUES('s13', 2, 9.5, 'P');
INSERT INTO EXAM VALUES('s13', 3, 2.1, 'F');
INSERT INTO EXAM VALUES('s14', 1, 9.2, 'P');
INSERT INTO EXAM VALUES('s15', 1, 9.7, 'P');
INSERT INTO EXAM VALUES('s15', 2, 1.7, 'F');
INSERT INTO EXAM VALUES('s16', 1, 8.4, 'P');
INSERT INTO EXAM VALUES('s17', 1, 9.3, 'P');
INSERT INTO EXAM VALUES('s17', 2, 9.9, 'P');
INSERT INTO EXAM VALUES('s17', 3, 1.3, 'F');
INSERT INTO EXAM VALUES('s18', 1, 9.9, 'P');
INSERT INTO EXAM VALUES('s19', 1, 9.4, 'P');
INSERT INTO EXAM VALUES('s19', 2, 8.9, 'P');
INSERT INTO EXAM VALUES('s19', 3, 7.4, 'F');
INSERT INTO EXAM VALUES('s20', 1, 8.1, 'P');
INSERT INTO EXAM VALUES('s20', 2, 6.4, 'F');
INSERT INTO EXAM VALUES('s21', 1, 9.5, 'P');
INSERT INTO EXAM VALUES('s21', 2, 8.8, 'P');
INSERT INTO EXAM VALUES('s21', 3, 8.2, 'P');[UPDATE]
INSERT INTO STUDENT VALUES('s0', '수강생', '20220331', 'M', '01000000005', 'm1');UPDATE STUDENT SET major_code= 'm2' where student_code= 's0';
[DELETE]
DELETE FROM STUDENT WHERE student_code = 's0';
[SELECT]
SELECT * FROM STUDENT;
-- 학생 데이터 전체 조회
SELECT * FROM STUDENT WHERE STUDENT_CODE ='s1';
-- 학생코드가 S1인 테이블 조회
SELECT name,MAJOR_CODE FROM STUDENT WHERE STUDENT_CODE = 's1';
-- 학생코드가 S1인 데이터의 이름과 MAJOR_CODE 조회
[JOIN]
SELECT s.name, s.major_code, m.major_name FROM STUDENT s JOIN MAJOR m ON s.major_code = m.major_code;
-- JOIN으로 얻은 값
SELECT s.name, s.major_code, m.major_name FROM STUDENT s, MAJOR m WHERE s.major_code = m.major_code;
-- JOIN을 쓰지 않고 얻은 값
-- 2개 다 동일함
❗ JOIN 이해하기
JOIN은 나누어진 테이블을 하나로 합치기 위해 데이터베이스가 제공하는 기능이다. JOIN 은 ON이라는 키워드를 통해 기준이 되는 컬럼을 선택하여 2개의 테이블을 합쳐준다. JOIN을 할 때에는 적어도 하나의 컬럼을 서로 공유하고 있어야 하기 때문에 테이블에 외래키가 설정 되어 있다면 해당 컬럼을 통해 JOIN을 하면 해당 조건을 충족할 수 있다.
다만 JOIN을 하기 위해 외래키를 설정하는 것이 항상 좋은 선택이 아닐 수도 있다.
→ 외래키를 설정하면 데이터 무결성을 확인하는 추가 연산이 발생한다. 또한 무결성을 지켜야하기 때문에 상황에 따라 개발하는데 불편할 수 있다.
👉 결론은 항상 테이블에 모든 제약조건을 걸어야 하는 것은 아니다. 프로젝트의 상황에 따라 가장 효율적인 제약조건을 테이블에 적용해야한다.
▶️ 문제
👉 수강생을 관리하는 MANAGER 테이블을 만들어보세요.
1. 컬럼은 총 id, name, student_code 입니다.
2. id는 bigint 타입이며 PK입니다.
3. name은 최소 2자 이상, varchar 타입, not null 입니다.
4. student_code는 STUDENT 테이블을 참조하는 FK이며 not null 입니다.
5. FK는 CONSTRAINT 이름을 ‘manager_fk_student_code’ 로 지정해야합니다.
6. comment를 사용해서 컬럼과 테이블에 설명을 추가합니다. (맥만)
CREATE TABLE IF NOT EXISTS MANAGER
(
id bigint not null primary key comment 'PK',
name varchar(100) not null comment '매니저이름',
student_code varchar(100) not null comment '수강생코드',
CONSTRAINT manager_fk_student_code FOREIGN KEY (student_code) REFERENCES STUDENT(STUDENT_CODE)
)👉 ALTER, MODIFY를 이용하여 MANAGER 테이블의 id 컬럼에 AUTO_INCREMENT 기능을 부여하세요.
ALTER TABLE MANAGER ALTER COLUMN id bigint auto_increment;👉 INSERT를 이용하여 수강생 s1, s2, s3, s4, s5를 관리하는 managerA와 s6, s7, s8, s9를 관리하는 managerB를 추가하세요. (AUTO_INCREMENT 기능 활용)
AUTO_INCREMENT를 어케 이용하란거지????
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerA', 's1');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerA', 's2');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerA', 's3');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerA', 's4');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerA', 's5');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerB', 's6');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerB', 's7');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerB', 's8');
INSERT INTO MANAGER(NAME, STUDENT_CODE) VALUES ('managerB', 's9');👉 JOIN을 사용하여 managerA가 관리하는 수강생들의 이름과 시험 주차 별 성적을 가져오세요.
SELECT e.EXAM_SEQ, e.SCORE, s.NAME
FROM MANAGER m JOIN STUDENT s on m.STUDENT_CODE = s.STUDENT_CODE
JOIN EXAM e on m.STUDENT_CODE = e.STUDENT_CODE WHERE m.NAME = 'managerA';👉 STUDENT 테이블에서 s1 수강생을 삭제했을 때 EXAM에 있는 s1수강생의 시험성적과 MANAGER의 managerA가 관리하는 수강생 목록에 자동으로 삭제될 수 있도록 하세요.
(ALTER, DROP, MODIFY, CASCADE 를 사용하여 EXAM, MANAGER 테이블 수정)
ALTER TABLE EXAM
DROP CONSTRAINT exam_fk_student_code;
ALTER TABLE EXAM
ADD CONSTRAINT exam_fk_student_code FOREIGN KEY (student_code) REFERENCES STUDENT (student_code) ON DELETE CASCADE;
ALTER TABLE MANAGER
DROP CONSTRAINT manager_fk_student_code;
ALTER TABLE MANAGER
ADD CONSTRAINT manager_fk_student_code FOREIGN KEY (student_code) REFERENCES STUDENT (student_code) ON DELETE CASCADE;
DELETE
FROM STUDENT
WHERE student_code = 's1';
끼약,,,,기빨렸어,,,,,